100 多天后,大语言模型能胜任邮件通讯主编吗?|Digital Explorer#033
被 AI 「替代」并不是技术命题,而是一个对于职业道德的认知命题。


Editor’s Note
今年春节期间,我首次尝试让「AI 编辑」替代我的工作,撰写、编辑了多期「Dailyio Briefing」,随后我在一期 Digital Explorer 里回顾了整个流程,还没来得及阅读的朋友可以在这里了解一下。
过去两周经历了一次久违的搬家之旅,「AI 编辑」重新登场,主理了四期「Dailyio Briefing」(原计划出版五期)。
从 2 月中旬到 5 月下旬,这 100 多天的时间里,各类语言模型的发展,是否让我——一个长期关注大模型发展的内容创作者——感受到变化?各类模型如何影响和改变我的内容创造流程?以及,接下来的 100 多天,还会有哪些值得关注的方向?这期 Digital Explorer 的特刊,我们就来聊聊这些话题。
基础模型能力越来越强
过去 100 多天,从闭源模型到开源模型,几乎都经历了一个代际的迭代,先看闭源模型:
- Anthropic 公司发布 Claude 3 系列,其中 Opus 型号一跃成为业界最强模型;
- Mistral 发布三款闭源模型,Large 型号在众多场景里都有不错的表现;
- OpenAI 推出 GPT-4o,除了多模态的优化之外,还极大提升了反应速度;
- Google 先后推出多款 Gemini 模型,并将上下文窗口拓展到百万 Token 级别;
而开源模型领域也有新发展:
- Meta 发布 Llama 3,包括 8b 和 70b 两个型号;
- Mistral 开源 Mixtral 8x22B;
- 阿里云持续发布 70b、110b 参数规模的开源模型;
- Cohere 推出多语言开源模型 Command R+;
新一代基础模型——无论是商业模型还是开源模型——的能力都有大幅提升。其中我认为最重要的两点:其一是更大的上下文窗口;其二是多模态能力。
上下文窗口的迭代速度非常快,从 4k、8k 的上下文到 65k、200k 甚至 100M,如此大的上下文窗口极大提升了内容处理的效率。
比如之前我想分析或总结一些长文,即便是在 8k 的上下文窗口里,也需要将单个文本切割到 4k 或 6k Token 左右,这个过程耗时耗力,而现在,类似《纽约客》的「万字长文」甚至几十万字的图书内容,都可以直接扔到大模型应用里。
其次,多模态能力的提升,使得模型能够更快处理诸如图片、音频等内容,结合更大的上下文窗口,丰富了大模型的使用场景,特别是 GPT-4o 所展示的音频处理能力,依稀让人看到一个全新的人机交互入口。

更进一步来看,大模型的「创造」能力也在显著提升,100 多天前,我不敢奢望某个模型可以真正成为我的写作助理,比如模仿我的内容风格写一段草稿。但自从 Claude 3 Opus 发布之后,我发现这款模型已然具备了强大的模仿特定风格进行撰稿的潜力,仅仅通过 Few Shot 等简单的提示设计,就能够实现非常好的效果。
模型的使用门槛正在大幅降低
回想 100 多天前,我使用 ChatGPT、Perplexity 和部分开源模型构建工作流程,很多时候,我需要精心计算各类模型的使用成本,特别是要平衡 ChatGPT Plus 订阅制与各类模型 API 即用即付之间的关系。
而从 4 月开始,无论是商业模型还是开源模型,绝大多数模型都在大幅降低使用价格。究其原因,既有市场扩张的考量,也得益于技术进步带来的成本下降。
Gemini 1.5 Flash、Claude 3 Haiku 就是低价但质(量)高的商业模型代表,开源模型里,Mixtral 8x22B 兼具了低价、速度与能力等多重优势。
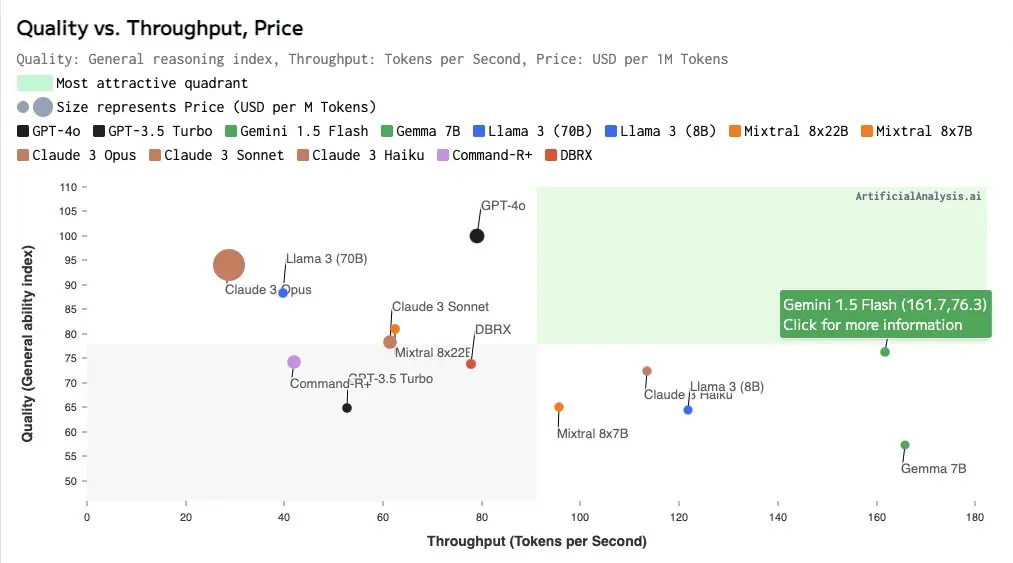
与此同时,各类模型的获取门槛也在大幅下降,Claude 开放 API 之后,使用 Claude 3 系列模型的门槛大大降低;而诸如 OpenRouter、Together AI 等模型聚合平台,提供了一站式测试、部署各类商业模型、开源模型的便捷通道。
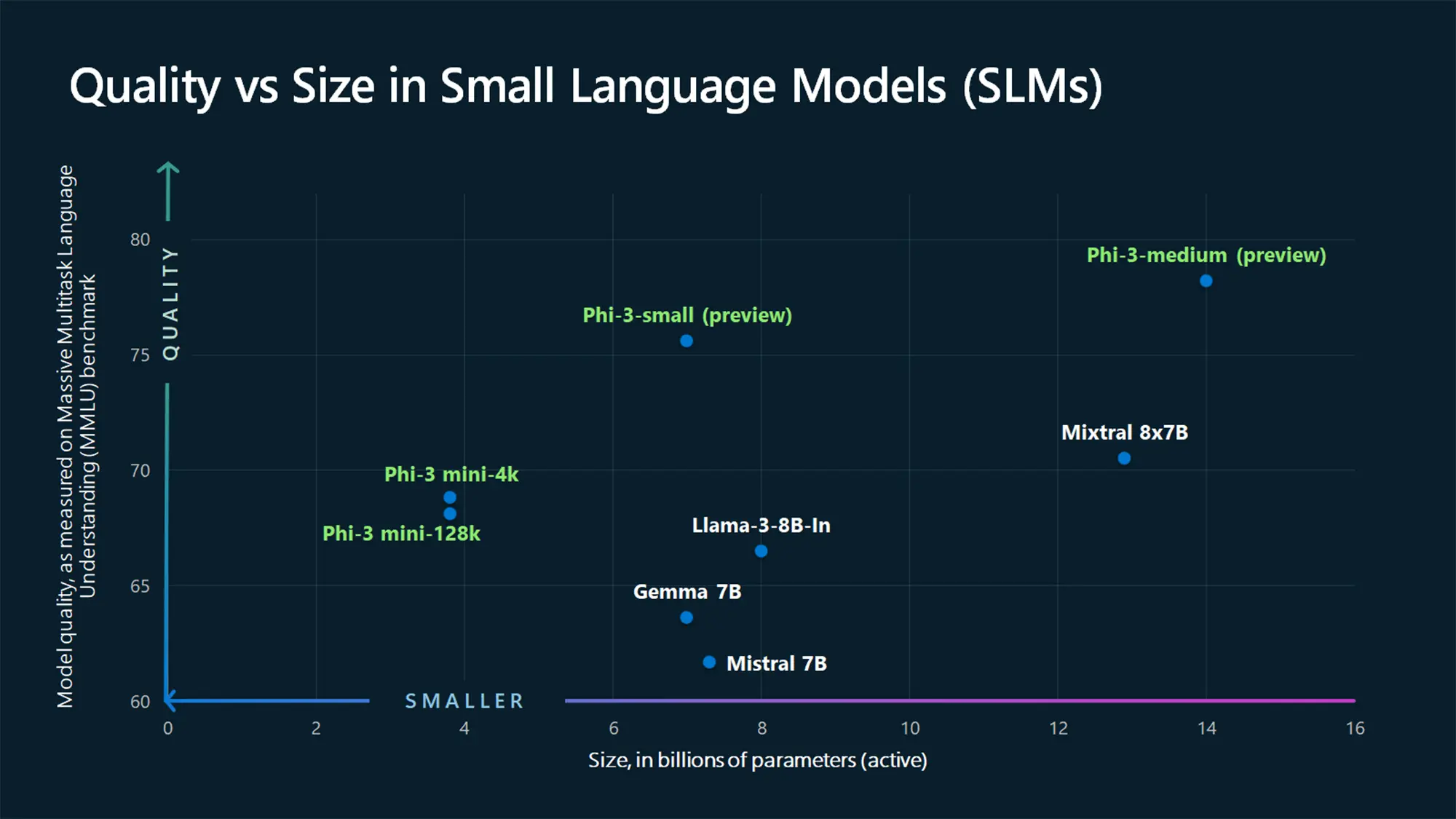
第三,随着小模型的增多,代表如 Phi-3 系列,进一步降低了「本地使用大模型」的硬件门槛,仅以搭载 M 系列处理器的 MacBook 为例,16GB 内存已经可以运行 Llama 3 8b,你可以使用 Ollama 或 LM Studio 下载、运行一系列本地开源模型。
正是在成本、API 接入门槛以及本地运行模型门槛的下降,现阶段我使用大模型的方式已经和年初发生了很大变化,我会将工作任务首先分类,基于场景和任务难度安排使用不同的模型,几个简单的例子:
- 翻译场景:需要多语言的支持能力,此时小模型的 Cohere Command R+、Qwen 1.5-110B 非常合适,相反 Claude Haiku 就比较差;
- 文本总结场景:需要较好的理解能力,而且很多时候还需要较长的上下文窗口,此时 Mistral 8*22B(65K 上下文)的表现就可能比 Llama 3 70B(8K 上下文)更好;
- 内容生成场景:现阶段除了 Claude 3 Opus 和 GPT-4,其他模型的表现都不稳定;
关于这部分的详细内容,可参见第 32 期 Digital Explorer 里的分享。