DeepMind 为什么错过了 ChatGPT 时刻?
《无限机器》真正值得读的地方,是它解释了 DeepMind 的技术信念为何失速,又为何重新变得重要。


Editor’s Note
🗓️ 2026.04.28 | Poe
DeepMind 不是没有语言模型,也不是不懂 Transformer。它的问题更复杂:这家公司太相信「智能必须来自行动、反馈和现实世界的根基」,也太相信强大 AI 应该被更谨慎地释放。
然后 ChatGPT 出现了。
一个看起来粗糙、依赖互联网文本、通过「预测下一个词」扩展出来的产品,率先占领了用户界面,也重新分配了行业注意力、资本和人才。DeepMind 曾经用 AlphaGo 和 AlphaFold 证明机器可以在受控环境中生成超越人类的知识,却在大模型产品化的第一波浪潮中被迫追赶。
Sebastian Mallaby 的新书《无限机器》表面上写 DeepMind 和 Demis Hassabis,真正值得读的地方,是它把一个更深的问题摆了出来:当科学理想遇到算力、资本和产品竞争,AI 实验室还能决定自己的方向吗?
这篇书评从 DeepMind 的强化学习信念写起,讨论它为什么错过 ChatGPT 时刻,也讨论一个更有现实意义的反转:当 o1、DeepSeek R1 和测试时计算成为新焦点,DeepMind 早年坚持的「经验」路线,正在重新回到 AI 竞赛中心。
1945 年,曼哈顿计划进入最后阶段时,Robert Oppenheimer 和他的同事们正在制造一种足以毁灭人类的武器。多年后,当被问及为何明知后果可怕却依然推进时,Oppenheimer 给出了一个令人不安的回答:「当你看到某种在技术上极其甜美(technically sweet)的东西时,你就会放手去做。你只有在取得技术上的成功之后,才会去争论该拿它怎么办。」
七十多年后,类似的问题也出现在人工智能研究者面前。
2015 年,在伦敦皇家学会的一场私下交谈中,深度学习的重要奠基人 Geoffrey Hinton 承认,一旦机器智能真正起飞,人类将很难阻止它被滥用,甚至可能面临严重后果。当被问及为何还要继续这项研究时,Hinton 的回答与 Oppenheimer 有相似之处:他当然可以给出许多常规理由,但更深处的原因是,探索本身的吸引力往往会压过对未知后果的恐惧。
这种对技术可行性的迷恋,也是 Sebastian Mallaby 新书《无限机器》(The Infinity Machine)反复追问的问题。
作为《富可敌国》的作者,Mallaby 这一次把目光投向 DeepMind 及其创始人 Demis Hassabis。书中写到 DeepMind 从伦敦早期创业阶段走向 AlphaFold 和诺贝尔化学奖的过程,但它并不是一本常见的硅谷创业成功故事。
对今天的科技从业者和投资人来说,这本书的价值在于,它提供了一个更长时段的参照系。它让我们看到,大语言模型与强化学习并不只是两条技术路线,也代表两种理解智能的方式。它也写出了那些希望以科学理想约束资本力量的人,最终如何被算力、市场竞争和公司治理的现实重新塑形。
游戏玩家与现实的计算法则
要理解 DeepMind 的技术气质,要先理解 Demis Hassabis 的经历。
许多硅谷 AI 创业者更接近工程师或黑客。他们相信快速迭代、产品发布和规模扩张。Hassabis 的背景不同。他是国际象棋神童、电子游戏设计师,也受过认知神经科学训练。
对于一个从小在棋盘的 64 个方格中寻找最优解、十几岁时就参与开发《主题公园》这类复杂模拟游戏的人来说,现实世界并非不可分解的神秘对象。它更像一个由信息、规则和反馈组成的巨大系统。
在这种世界观里,如果宇宙的底层逻辑可以被理解为信息,那么物理、化学和生物中的复杂现象,就都有可能被能够识别模式的机器重新解释。
这直接影响了 DeepMind 早期的技术选择:强化学习(Reinforcement Learning)。
在 OpenAI 后来依靠规模扩展取得突破之前,DeepMind 的代表性成果来自另一种路径。从 Atari 游戏,到击败李世石的 AlphaGo,再到征服复杂即时战略游戏的 AlphaStar,DeepMind 的 AI 并不是简单学习人类已经写下的知识。它在一个规则和奖励机制相对明确的环境中,通过大量自我对弈和试错,逐渐形成超越人类经验的策略。
Hassabis 和他的首席科学家 David Silver 都相信,人类知识既有边界,也带有偏见。如果 AI 只学习人类留下的数据,它最多只能模仿人类。要接近更高层次的智能,机器必须在环境中行动、反馈、调整,并从中提取人类不一定能直接看见的规律。
AlphaGo 下出的「第 37 手」之所以令人震动,不只是因为它赢了棋局,而是因为它显示出一种不依赖人类棋谱的策略能力。它不像是人类经验的延伸,更像是机器在规则空间中自行找到的另一种可能。
这种思路在生物学领域获得了最重要的成果,也就是 AlphaFold。
面对蛋白质折叠这个困扰生物学界多年的问题,DeepMind 最终没有完全依赖传统物理模拟,而是借助深度学习和搜索机制,在大量氨基酸序列中识别蛋白质结构的统计规律。Hassabis 用计算证明,只要现实世界的约束条件足够清楚,机器就可能在巨大的可能性空间中找到高度可靠的答案。
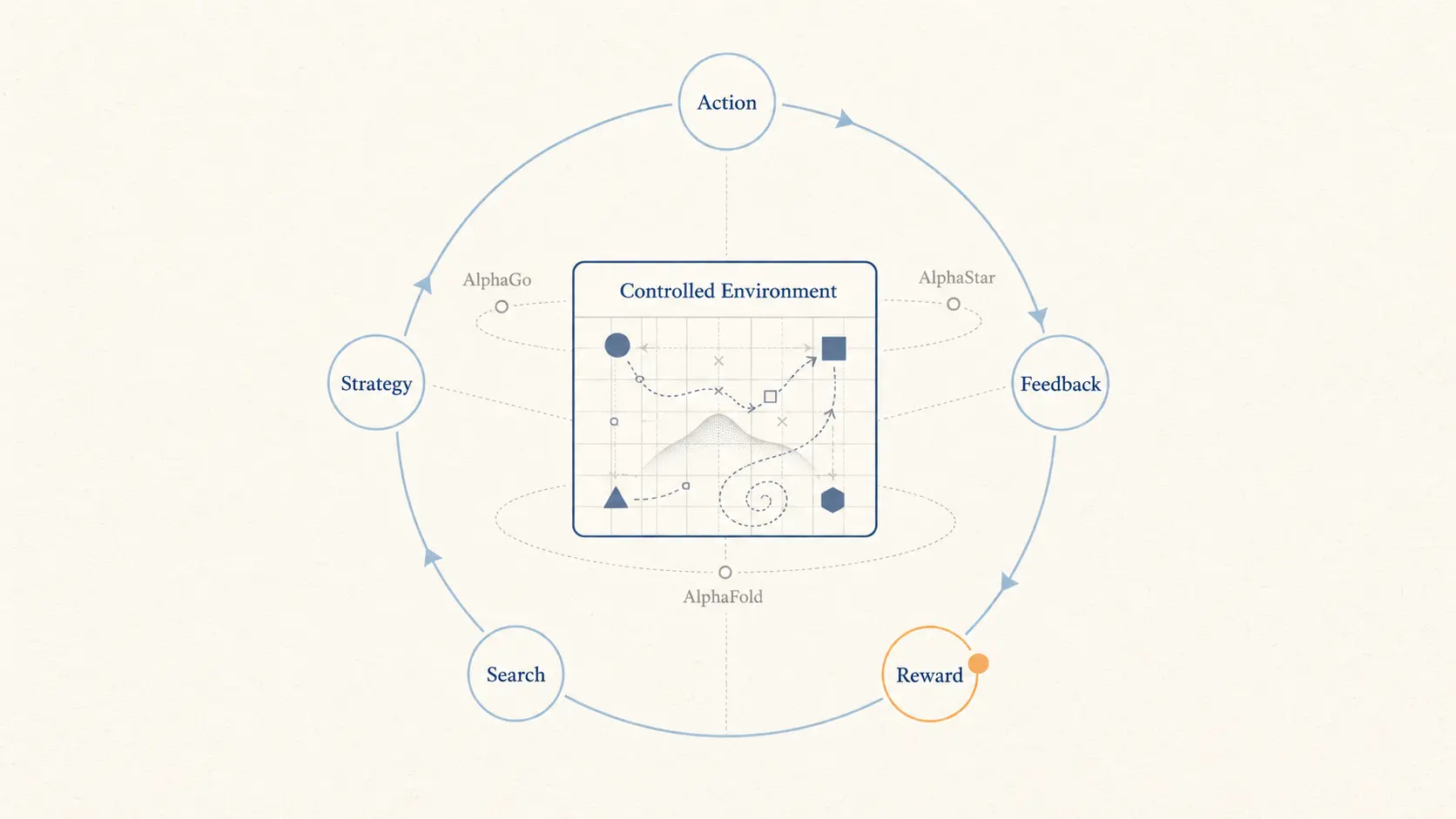
但同样的技术信念,也让 DeepMind 在生成式 AI 浪潮中显得迟疑。
DeepMind 擅长的是规则明确、反馈可衡量、环境相对封闭的问题。棋盘如此,游戏如此,蛋白质结构预测也在某种意义上如此。可是语言世界更混乱。它充满隐喻、歧义、社会经验和没有明确奖励函数的人类表达。
也正是在这里,DeepMind 和 OpenAI 走向了不同方向。
DeepMind 为什么错过 ChatGPT 时刻
如果说 DeepMind 的气质更接近贝尔实验室,追求封闭环境中的基础科学突破,那么 OpenAI 更像一家典型的硅谷初创公司。它更愿意接受粗糙但可扩展的工程路径,也更愿意把不完美的技术推到用户面前。
《无限机器》中写到一个关键场景。
2017 年,Google 发布奠定今天大模型基础的 Transformer 论文后,DeepMind 的反应相对冷淡。Hassabis 对单纯的语言模型持怀疑态度。他认为语言只是符号,缺少与现实世界的物理交互。一个模型就算读完维基百科,也不等于真正理解重力、情感和因果关系。没有「根基(grounding)」的模型,很难通向通用人工智能。
Ilya Sutskever 作出了相反判断。
在他看来,只要神经网络足够大,数据足够多,通过看似简单的「预测下一个词」,模型内部就可能建立某种世界模型。它不需要直接体验重力,也可能通过大量文本形成对重力的常识;它不需要拥有情感,也可能从人类表达中学习情感的结构。
两种路线的分歧在这里变得清楚。
DeepMind 希望机器在受控环境中从零推演规律。OpenAI 则选择把公开互联网文本和人类文明留下的大量表达交给一个足够大的神经网络,让模型在规模中自行形成能力。
结果已经写进技术史。ChatGPT 的发布迫使 DeepMind 重新面对自己的路线选择。
DeepMind 并非没有语言模型。它内部曾研发 Gopher 和 Sparrow 等系统。但出于安全顾虑、产品化谨慎,以及 Google 体系内对声誉风险的敏感,这些模型并没有像 ChatGPT 那样迅速进入大众市场。
这不是单纯的技术失败。更准确地说,它是技术信念、组织文化和商业节奏之间的错位。