从 Tiddlywiki 到 ChatIO,大模型驱动的内容复用进化之旅|Digital Explorer#049
解锁内容复用的 AI 魔法。

Editor’s Note
今天是 2024 年 12 月 24 日,您正在阅读的是第 49 期 Digital Explorer,本期为 Dailyio 会员免费内容,欢迎成为会员获取。
作为内容工作者,我一直希望可以高效复用过往内容,实现内容「一次撰写、多次使用」的目标。过去几年,我在各类笔记工具里做了尝试,但效果都不好,最近几个月,我开始利用 Open WebUI 与各类大模型构建内容复用机制,效果如何呢?本期带来详细分析。
Gemini 新功能「深度研究」初体验、GitHub 里可「合法白嫖」的免费大模型资源、OpenRouter 发布「BYOK」功能等,也是本期关注的话题。
🔥 大模型·焦点
ChatIO 与 Open WebUI 的内容复用实践
ChatIO 最近推出了几个「AI 助理」,通过整合过去五年 Dailyio 各类会员通讯的内容,可以针对数字工具、AI 产业分析以及深度阅读的场景给出回答和建议。
其实这个功能并不神秘,本质上也是一个 Rag 的应用场景。利用嵌入模型将文档内容向量化,然后当用户提问的时候,使用诸如 Gemini 2.0 Flash 这样的基础模型进行回答。
在正式上线 ChatIO 之前,我大概测试了一个半月的时间,一方面是为了测试功能和体验,另一方面也在思考信息再组合与复用的新可能性。
作为内容工作者,我一直希望可以高效复用过往内容,实现内容「一次撰写、多次使用」的目标。因为很多时候,内容创作并非从零开始,你需要结合过往——无论是大脑里没有条理的记忆、自己曾经精心整理过的笔记抑或是已经写过的内容——这些「内容」都可以作为未来创作的新素材。
此前几年,我曾在 Tiddlywiki 里尝试过内容复用,寄希望于通过剪辑和组合的方式,形成新的内容生产流程。
但问题也很多。一方面,这是一个需要完全手工的工作,比如我需要检索到相应内容,可能是一段话或几段话,然后进行标记,一般就是创建各类自定义的字段,以至于整个条目变得非常复杂:
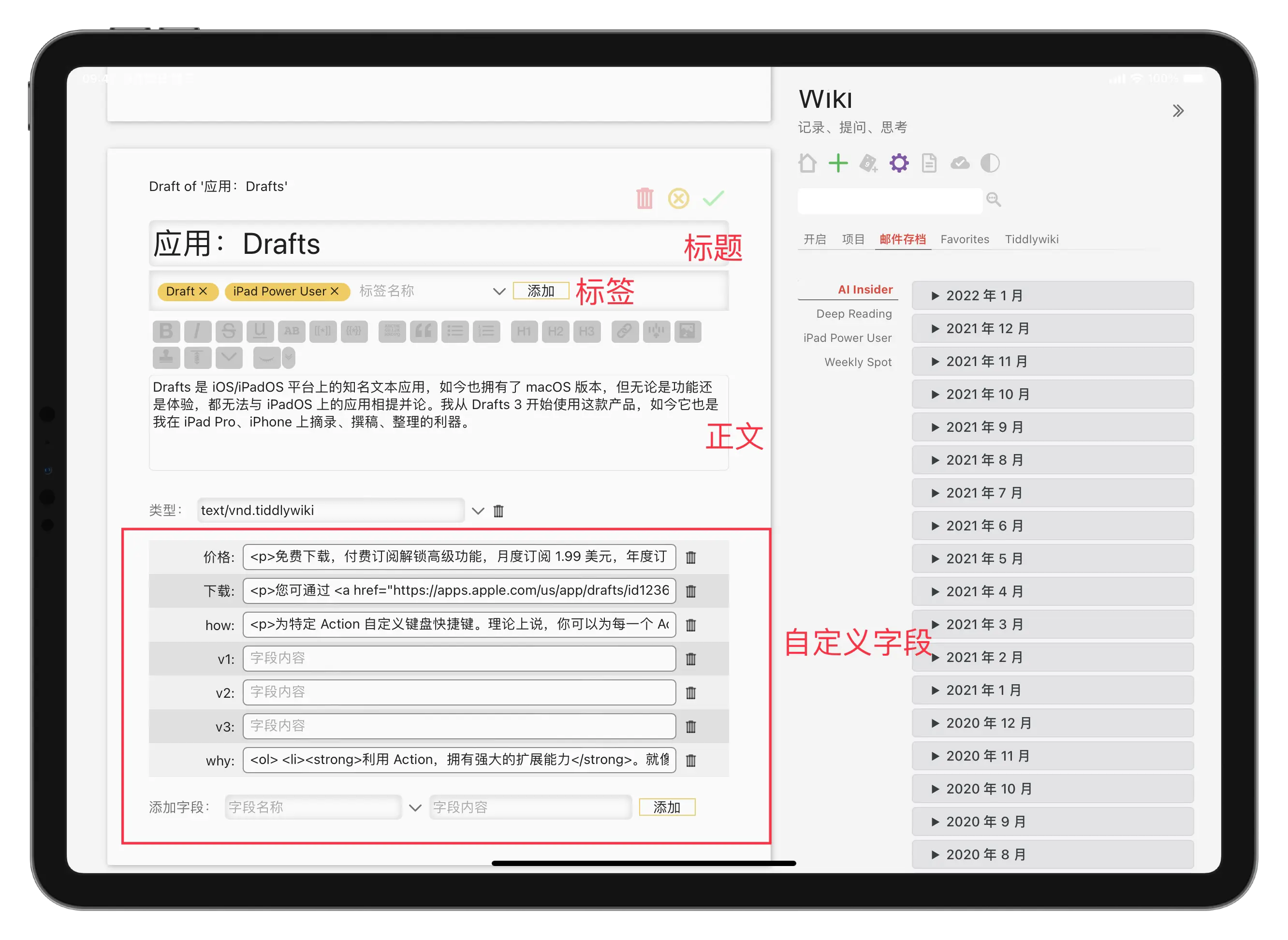
另一方面,内容复用也有一定的场景需要。一般情况下,我们再次使用之前的内容的方式包括:
- 在笔记库或内容库里检索特定关键词;
- 复制某一段话或几段话到新文档;
- 根据新文档的情境进行修改;
而内容调取由于是一种自动化的过程,只能呈现出特定内容,我无法在新条目里修改这些内容,只能在原条目——也就是上图里的各种字段里修订,这使得很多时候的内容调用,变成了对原条目的修改过程。
这也很容易引发了一系列问题,比如某个条目已经被多次调用,如果我修改了其中一个字段,可能会影响到其他条目的正确显示,造成更大范围的混乱。
所以我很快放弃了使用 Tiddlywiki 作为内容复用工具的想法,后来,我也在 Obsidian、Craft 等工具里尝试过类似的想法,两者都可以以一个段落作为处理对象,灵活调用。但使用起来的效果并不理想,比如 Obsidian 的「嵌入」往往带有一个「小尾巴」,而且也只能跳转到原来的笔记里进行修改,这实际上也和 Tiddlywiki 的问题一样:

ChatGPT 等大语言模型流行起来之后,我开始思考如何围绕大模型构建内容复用的流程,我希望让大模型根据我之前的内容,有「创意」地生产一些新内容,当然,这需要几个基本条件:
- 强大的文本嵌入模型,可以实现高效、快速的文本向量化;
- 强大的文本对话模型,能够快速且高质量地生成新内容;
- 项目开源或免费,至少拥有一定的定制能力;
去年我在 Dify、FastGPT 等项目中都做过尝试。要么工具使用起来比较复杂,要么就是因为模型能力不足导致整体体验比较糟糕,直到今年我开始重度使用 Open WebUI,我发现它可以实现我的一些想法。
首先,Open WebUI 提供了丰富的大模型接入机制,不必完全依靠 OpenAI。
过去一年来,OpenAI 的竞品们的能力都有大幅提升,无论是闭源模型还是开放权重模型,已然具备了价格与能力的平衡优势,我们既可以使用 Claude 3.5 Sonnet 处理复杂的文本生成任务,还可以借助「便宜又大碗」的开放权重模型应对一些简单工作。
其次,Open WebUI 的开源机制,能够借助开源社区的力量加速产品的迭代,从产品本体优化到借助各类函数、Pipeline,Open WebUI 的可用性——相比于一年前——已经有了大幅提升。
第三,Open WebUI 的帐号隔离机制,可以让我将自己的方法论作为一项产品提供给更多读者朋友,这也满足了我一直以来最朴素的一个想法:将 Dailyio 变成一个类似数据库的东西,读者可以从中浏览、检索获得一些有价值的内容。
当我将 Dailyio 过去五年多来的邮件通讯上传到 ChatIO 之后,新的内容复用流程也在悄然启动,比如让基于 Digital Explorer 内容的「Nexus」助理「撰写」年度总结如何:

或者,如果我想获得一些关于新年的长文,「Sage」助理会给出一些建议:

再或者,让 AI 分析师「Atlas」帮我发现 AI 领域垄断问题的线索:

当然,这些草稿、建议或线索不可能自然而言成为新的内容,但它们都基于过往内容进行「创作」,利用诸如 Claude 3.5 Sonet 或 Gemini 2.0 Flash 等模型重新组织,能够提供比简单搜索更好的内容建议,极大提升了进行内容复用的效率。
更进一步,鉴于大模型的基础能力还在进化,特别是大量具有推理能力的模型开始流行,我相信未来半年,基于大模型的内容复用机制将会迎来更多新的可能。
现在,ChatIO 里的三个助理已免费面向 Dailyio Premium 会员开放,您可根据自己的实际需求进行调用,在这个场景里,大模型已经成为内容分发的一种新形式。
ChatIO 现在也支持单独订阅,12 月 31 日前订阅该产品,首月可获得 20% 的折扣。
与此同时,如果您也有类似的需求,比如要把若干文档交给模型处理,然后回答或生成一些新内容,Open WebUI 很值得一试,毕竟它的部署方式多样且灵活,可放在本地或云端,一行 Docker 命令就解决了问题,还能与 Ollama 整合在一起。
另外,AnythingLLM 可以作为一个不错的「替补」,它拥有桌面和服务器不同版本,更偏向于 Rag 场景,但体验一般,无论是桌面还是服务器上,都会比较卡顿。
第二,对于嵌入模型的选择,我个人推荐 Cohere 最新的 Embed Multilingual v3 模型,基础能力好而且速度快,价格也非常适中,详见这款模型的文档。
第三,就像机器学习领域一句老话所指,「Garbage in,Garbage out」,一定要注意提供给大模型的数据质量,当然这方面没有统一的标准,各位朋友需要结合自己的实际场景,优化数据质量,这是让大模型「说出人话」的关键。
第四,当工具、模型、数据准备完毕,引导模型输出内容的提示词也非常关键,这也是一个没有「标准答案」的问题。
我个人的建议,对于绝大多数朋友来说,完全没有必要去花太多时间研究提示词的结构或写法,你只需将自己的需求以清晰的语言表达出来,然后借助一些提示词增强工具(类似优化提示词的提示词)进行优化,下面是几个可以尝试的提示词增强工具:
- 宝玉老师分享的 OpenAI 官方提示词增强工具;
- 适用于 Claude 的提示词增强工具,我个人测试的效果非常棒;
最后,我也在思考如何将 Dailyio 过去几年的内容数据如何开放出去,让各位朋友自己根据自己的需要,满足更灵活的使用需求,如果你有什么好的想法,欢迎写邮件告诉我。
大模型·应用
Google 最近为 Gemini 服务引入了「深度研究」功能,这可以看作是 Google 首个 AI Agent:
我尝试了几个测试,比如使用某家公司的股价分析了解其对事实数据的整合能力,它的逻辑是检索大量网站,然后生成一份报告,存放在 Google Doc 里,但生成速度很慢:
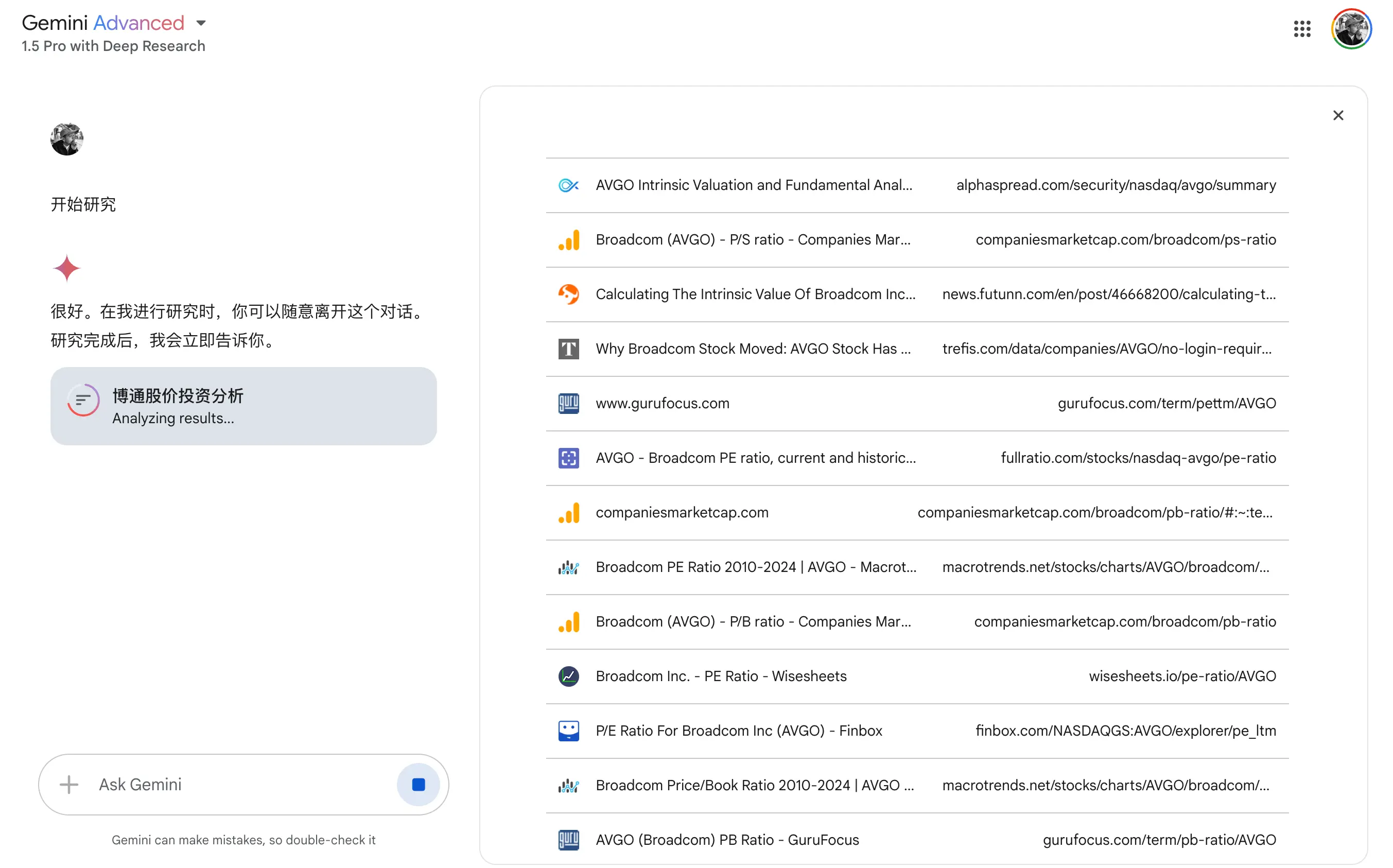
报告的结果只能说差强人意,尽管看起来很专业,但也会存在明显的数据错误,比如将去年的数据误认为是最新数据,这对于投资决策来说是不可接受的。
而在信息整合能力的测试中,「深度研究」展现出了独特优势:
- 能够快速收集多个平台的信息
- 提供相对客观的对比分析
- 生成结构化的分析报告
在我看来,Gemini 的这项功能更像是一个高效的信息收集工具,而非专业的分析系统。用户在使用时需要对其输出保持警惕,特别是在处理需要高度准确性的领域时,一定要核实数据和事实。
目前该功能需要订阅 Google One 的 AI Premium 套餐才能使用,价格为 19.99 美元/月。
GitHub Copilot 功能向所有用户免费提供。这个功能是 GitHub 的 AI 辅助编程工具,既可以作为插件集成到 IDE(比如 VS Code),也可以在网页上直接使用。
免费版本每月限制 2000 条代码建议、50 条 Copilot Chat 消息,可调用 Anthropic 的 Claude 3.5 Sonnet 或 OpenAI 的 GPT-4o 模型。
另外,GitHub 还有一个免费的大模型使用计划,提供包括 GPT-4o、Mistral Large 在内的众多模型选择,虽然有一定的额度限制,但个人使用的话基本够用。
大模型调用平台 OpenRouter 发布全新「BOYK」功能,简单来说,就是用户可以添加自己的大模型 API Key,并设置优先调用自己的 Key 还是 OpenRouter 里的 Key,目前主要支持海外的大模型产品:
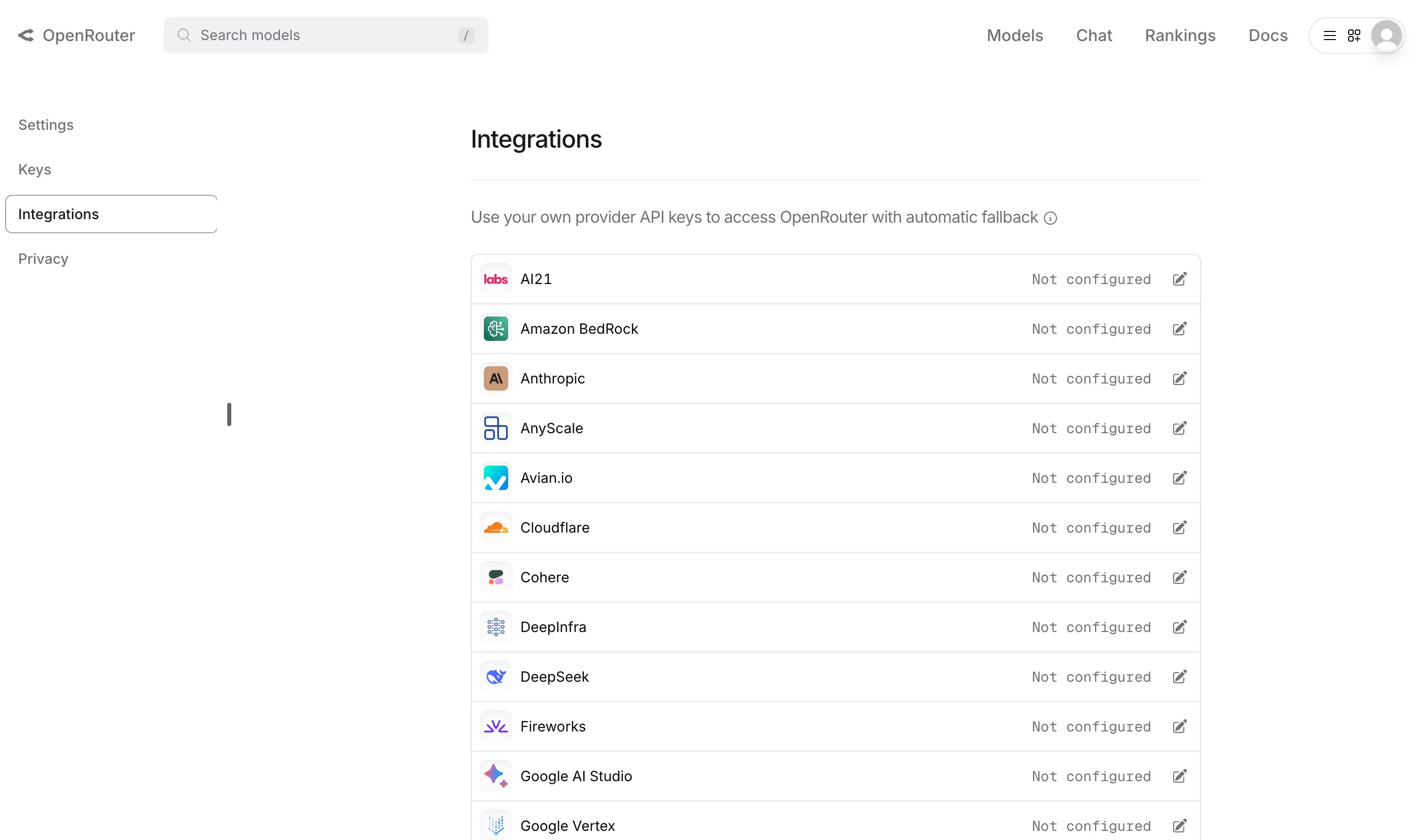
这个功能比较实用,它降低了管理各类大模型 API Key 的难度,可以借助 OpenRouter 的 API 进行统一调用。当然你也可以使用诸如 one-api 之类的项目实现类似的目的,但必须考虑到部署、运维的难度,另外还有安全的问题。
Claude 3.5 Haiku 现已全面上线 Claude 对话平台。之前的特定基准测试中,3.5 Haiku 的性能与上一代旗舰模型 3 Opus 相当甚至更胜一筹。Anthropic 表示,3.5 Haiku 特别适用于代码推荐、数据提取和标签、以及内容审核等任务。
不过需要提醒的是,该模型不支持图像分析。